Role of Digital Transformation in Achieving Operational Excellence in the Process Industries

What is Operational Excellence?
In the business world, the term “operational excellence” is becoming extremely popular. But what is “Operational Excellence”? We need to put Operational Excellence into context before we can define it. “Operational Excellence” refers to efforts made at the individual process level within a company. In reality, it necessitates using Deming’s Circle: design, execute, and improve any process.
Simply said, operational excellence means producing or providing goods and services to the highest possible standard. To begin, we can put it into action by optimizing at each level. It all starts with people, then processes, and finally resources or assets.
Operational excellence transforms a company that effectively conducts and executes value-driven activities safely and efficiently. Furthermore, digital transformation can assist businesses in achieving operational excellence and transitioning from automated to autonomous operations.
What is the current state of operational excellence in the process industries?
Numerous process sectors have so far tried to achieve operational excellence using a variety of ideas and techniques, but they have encountered various challenges with standardization, adoption, and scalability that have hindered their capacity to enhance and boost output quality.
The complexity of the process, its opaque operation, and the overall organizational culture’s resistance to change were the primary challenges.
Why to choose Digital Transformation?
The major role of digitalization is to assist in the reduction of the complexity of manually operated processes and the creation of a transparent overview of the process by utilizing the vast data available.
The following are some solutions that digital transformations bring specifically to process industries: data reporting solutions like dashboard development or asset health monitoring, overall equipment efficiency.
Data-driven solution models such as soft sensors, or advanced solutions such as predictive maintenance rather than heuristics/experience-based approach, which reduces reliance on trained/experienced people and shortens the training period for novice operators.
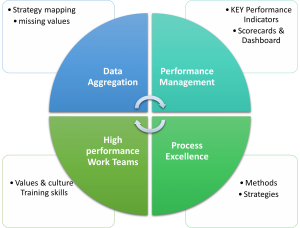
Operational excellence using Digitalization in the process industry
It entails using well-known and stable concepts of operational excellence in conjunction with digital solutions to improve the performance of people, processes, and assets; in other words, it will assist an industry in upskilling entire organizational culture. By narrowing the gap between departments and levels within the organization’s hierarchy.
Optimized Organizational Culture
Many industries have begun their digital transformation journeys, and those who have not yet begun their journeys plan to do so at various levels of digital transformation. According to a Fujitsu survey, 44 percent of respondents from offline firms believe that by 2025, more than half of their non-automated business operations will be automated.
Industries should be able to connect the stages of digital transformation; they need to know where they are in the process and what output they want, since alternative solutions can be supplied based on the requirements using a step-by-step method.
From the initial sensor installation to the conversion of manual data to digital data, the data is then centralized in DCS for control and monitoring. A reliable communication layer between the IT and OT networks, as well as an analytic solution for monitoring/modelling process data.
The Operating Training Stimulator (OTS) can also be developed to give new operators plant experience, bridging the gap between a trained and untrained operator. Data visualization and reporting ensure that the process is understood and clarified. Data can be utilized to build a first principal model and check the data’s theoretical and actual trends. For non-linear processes, data-driven models such as regression models can be created. Soft sensors for parameters with a given time lag are developed so that live empirical values are accessible before time, condition-based monitoring to ensure a batch follows a golden batch profile and we get the best yield.
Conclusion:
Upskilling of people, processes, and assets is a necessity for process industry, operational excellence and its principle’s assist in performing well in the process industry at all levels of the business. But hindrance due to complexity of the nature of operation in process industries became a major problem. Digital transformation reduced it by providing highest level of transparency in the manual operational process and upskilled individuals in the organizational hierarch.
Written by,
Adarsh Sambare and Kishan Nishad
Data Scientists
Tridiagonal Solutions
- Published in Blog
Optical Character Recognition – OCR in Manufacturing Industry


Introduction:
Despite digitization, most industries still rely on traditional methods for recording the data, such as manually filling out logs, excels, etc. But as the world moves into the digital age, industries are also making their way to storing data digitally.
To store a large amount of data, what steps should one take?
It would be helpful if we typed each word individually, wouldn’t it? It will be extremely tedious, time-consuming, and stressful to type every word. OCR technique comes in handy here. OCR stands for optical character recognition, part of computer vision technology. OCR allows you to convert different kinds of documents like images, pdf and scanned photos into machine-readable and editable forms.
What is OCR:
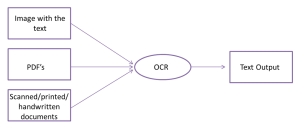
Optical Character Recognition (OCR) is a technique for extracting data from scanned documents. It uses either rule-based or AI-based approaches for recognizing text. The rule-based approach involved inspecting the area based on coordinates and hard-coded rules in the form of if-else statements. In contrast, AI-based OCR solutions develop rules on their own and continually improve them as they go along.
Rule-based approach are useful when extracting only a certain amount of information from a page and store it in tabular form for further analysis. The AI-based approach is suitable if all the information from the scanned page needs to extracted as it is without any modification.
How OCR Works:
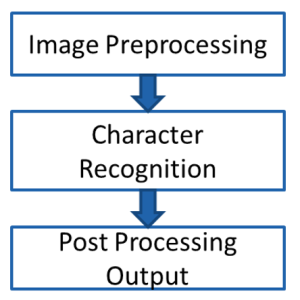
For the OCR technique to work effectively, we must process the image before feeding it to the engine. As part of preprocessing, we first convert the image into a grayscale and perform various morphological operations such as dilation, erosion, opening, and closing. This operation depends upon the kind of information you need to extract. For example, if you wish to extract simple text information contained in the image, simple operations like dilation and erosion work. However, information extraction from the table required intense morphological operations. Once information extracted, we performed a post-processing operation to get the data into the desired form.
Scope of OCR in the Manufacturing industries:
A batch ID, lot code, storage condition, and expiration date play a vital role in pharmaceutical data analysis. Each entry from the pdf report must be transcribed into an Excel sheet. It takes a lot of time and effort to complete this task. This effort could be saved by utilizing OCR technology. You can store the information in an Excel sheet after it is extracted from the pdf files.
It is common in the cement or chemical industry to store data in log sheets. OCR can extract this data and can output it as text. We further process that text output into a tabular form so the analyst team can analyze the process and act on the insight gathered from the data.
Many industries are using this technique to start their digitization journey, if you want to be part of this, connect with us at analytics@tridiagonal.com
Written By:
Nikhil Bokade
Data Scientist
Manufacturing Excellence Digital Transformation Group
- Published in Blog
Digital Transformation – Revolutionizing the Process Industry


Courtesy: Pixabay
Introduction
“Technology is best when it brings people together”
“Technology is best when you use it wisely”
“Data is the real evidence”
That’s right, today in this world of the digital era, we are all surrounded by digital technologies, tools & data. Everyone of us is now becoming a part of it, some driving it, and some being driven by it. For some, it’s incremental and for some it’s disruptive. But we all are the victim of this change.
There are mixed opinions on the adoption of these technologies, where for some it has brought huge realization in terms of ROI/monetary savings, whereas for some it has been futile. And with these opinions what would be your take?
In this article, our focus would be oriented more around the process and manufacturing space, which would fairly cover the space of oil & gas, spec. chem, pharma, heavy metals and other similar industry. This industry is heavily the function of the following: people, process and environment. Which means that, technology is expected to support and help each and every element of the industry.
Let’s dive a little deep into the core of digital transformation elements in process and manufacturing space.
Journey of Digital Transformation
Digital is the new revolution. The decisions are bound to be made through the insights and foresight what your data shows, and not solely based on your experience. This transformation is supposed to help you with intelligent systems that has the potential to increase the productivity, and performance in a sustainable way.
Technology being a major driver for this journey, also implies that, the group of users who shall be driving it need to have a strong hold on it, and should have a fair idea about its implications and consequences, if not handled well. Don’t worry, this article is not intended to trigger the alarm of fear in you, but rather to set off digital awareness. That’s right, “digital awareness” because, you are going to invest in an expensive, high-tech solution, which requires well-experienced drivers who are expected to be technology experts, and domain experts and has the same vision as that of the organization. It really starts with the identification of the first group of users and drivers who are going to utilize the technology, evaluate its functionalities and potential to satisfy the business KPIs. They really determine, whether the technology is going to be the high value solution or is it going be in vain. The adoption and scalability of the technology is going to be the function of the users representing the organization’s culture, with a strong understanding of the hierarchy and people in the organization, and then comes the digital readiness & processes and operations.
It’s not just an IT-solutions, rather, it’s a solution which has the potential to support and uplift all user groups at different levels and different teams- be it production, plant, maintenance, HR, IT, the management or any others.
In simple words, digital transformation is about automating the repetitive tasks, and supported with the informed decisions – upskilling the people and automating the process. Its all about identifying the digital driver, and digital levers?
Below is the schematic representation of how to strategize your operational excellence for digital transformation.

Fig. Strategize your Digital transformation roadmap for remote monitoring operations
Who should transform?
Anyone and everyone who has the set vision & goals for enhancing the work culture and bringing about the positive change and has a mission to think beyond the approach of siloed, centralized and disparate to collaborative, decentralized and orchestrated way of working should admire the benefits of digital transformation.
Operational/manufacturing excellence teams, whose task is to bring about benefits in the process and manufacturing through better and intelligent solutions can realize the benefits at various level. They can realize it through condition-based monitoring, predictive & prescriptive analytics, decision support systems and optimization in real-time. This has the potential to eliminate the shop floor variabilities, when it comes to experience based decisions, which is not backed by any beyond-human intelligence. One has to adopt such technologies which can add the layer of intelligence to the overall process and operations for making better and informed decisions. (https://dataanalytics.tridiagonal.com/digital-transformation-for-the-process-industry/)
Summary
Digital transformation is the new approach, and one has to adopt it before its too late. Technology itself cannot suffice the business requirements, rather it has to be applied on top of the human intelligence, which we apply on our routine-basis. Having the right drivers and stakeholders is a key to the successful implementation of digital transformation. Moreover, digital transformation has a huge potential in manufacturing and operations space, and one can start right from automating their regular and repetitive and manual tasks which currently is been performed on daily basis. It also helps the organization to look into their current challenges with a different lens and tangent, which could have been easily missed out otherwise.
Written by,
ParthPrasoon Sinha
Principal Engineer – Analytics
Tridiagonal Solutions
https://dataanalytics.tridiagonal.com/
- Published in Blog
Digital Transformation for the Process Industry

“Digital Transformation” is the adoption of the novel “Advanced Digital Technologies” to create modified processes from existing traditional processes. With Digital Transformation for the Process Industry being implemented in the Chemical/Manufacturing space, we have gained the realization that these tech stacks have high potential to achieve and improve efficiency, value.
Digital Transformation is a part of “INDUSTRY 4.0”, which involves wider concepts such as solutions on deep analytics, shop floor data sensor, smart warehouses, simulated changes, plus tracking assets and products. Industry 4.0 is an overall transformation taking place in the way goods are produced and delivered.
Process Industry is under constant pressure to meet the production target while minimizing the cost and maximizing product quality. Digital Transformation of the underlying assets can help them achieve this target. However, only incremental innovation and digital transformation have been seen in the last decade.
The major fundamental challenges in manufacturing process digitalization, are listed below:
- Outdated Systems
- Resistance to change (Disruptive V/S Incremental Change)
- Rigid Infrastructure
- Privacy Concerns
- Lack of Overall Digitization Strategy
In this article, an approach/ framework for digital transformation for the process industry will be discussed keeping the fundamental challenges in focus. A flexible framework that needs to change as per the industry requirements.
4 – Staged approach for an effective Digital Transformation in Manufacturing Space
Following are the stages for the journey of digital transformation:
- Stage: 1 Data Availability
- Stage: 2 Data & Asset Management
- Stage: 3 Data storage
- Stage: 4 Operationalizing the data
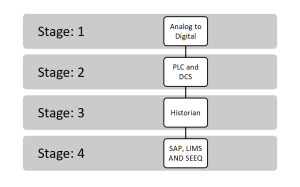
- Stage: 1 Data Availability
Utilization of manual operation or having limited or no digital control. But the manufacturer is ready to modernize its system from analog to digital. Focus being on adapting the right solution, sources of data, the adaption of the sensor, convert manual data to digital. One key aspect at this stage is to implement and integrate these sensors/IOTs, which follow the open protocols for communicating with the 3rd party applications.
- Stage: 2 Data & Asset Management
After the application of the sensor and converting manual data to digital, the data is then centralized to the PLC and DCS, to permit control, monitoring, and reportage of individual elements and processes at one location. This stage also becomes critical as basic instrumentation and controls would be the foundation for enterprise-wide digital solutions. It also makes us to think about the Integrity of the data – accuracy, consistency, completeness. Representation of data becomes very critical as we expect it to be speaking for the process itself, additionally maybe also about how the operations were considered on the shop floor.
- Stage: 3 Data Storage
Although DCS/SCADA enables the shop-floor team to take the decisions, but it is limited in terms of storing the historical data, which becomes a key for Digital transformation. To our rescue, comes the historian, which extends its capability to store large volume of data, additionally, today everyone is also talking about cloud-ready solutions, which provide us unlimited/remote storage/compute capability to process and derive the insights from our data.
- Stage: 4 Operationalizing the Data
Having your data available in the OT network still doesn’t help in operationalizing the data. Today, every Industry in targeting for remote monitoring, online notifications, and more. To achieve such targets, one really needs a robust layer of communication between the IT/OT network and moreover, an analytic solution for monitoring/modeling the process data. The COE team sitting remotely can monitor the real-time operations, support the operations with technological know-how.
Conclusion:
It is very much evident that Digital Transformation is of high-value journey for the Manufacturing / Process industry, but it really depends on the approach and the methodology which was undertaken to achieve the KPIs. Moreover, it also depends on the people who are involved in this journey of transformation. One needs to be well acquainted with technology, process challenges, the scope of improvements, and others.
Tridiagonal Solutions – a company specializing in providing knowledge/ insights-based solutions for the Process Industry. With strong process domain knowledge, we help companies in KPI-based advanced Analytics
Written by,
Adarsh Sambare
Data Scientist
Tridiagonal Solutions
https://dataanalytics.tridiagonal.com/
- Published in Blog
Machine Learning Model Monitoring in Process Industry (Post Deployment)


Machine learning by definition is a relationship which is established between a set of input variables and an output variable. Specifically, in process industry identification of this relationship becomes a difficult task, as it becomes highly non-linear at cases. The internal dynamics and behavior of the operator operating the process is something that comes under the interest of the ML/AI models. It tries to capture all of such instances which can be realized through the data it has been exposed to.
What’s Drifting in your Process – Data or Concept?
In this article, we are going to look into a very interesting and important concept of data-driven/Machine learning techniques. With the rapid development in technologies, industries have figured out multiple ways to estimate the performance of their deployed Machine learning/AI solution. One among them is drift – data drift and concept drift. Today, almost every industry is sitting on their-own data mine, longing enough to extract whatever information they could derive out of it. But, with such a surge in the industrial applications, it has also brought to our knowledge that there are lot many challenges involved at various levels of implementation. These challenges start right from the data itself – Integrity of the data, behavior and distribution of the data and so on. Sometimes, we end up spending most of our time in developing the process model (Machine learning model), which performs too well on the training dataset, but when tested on the live data- its performance drastically reduces. What do you think, what could have gone wrong here? Are we missing something or are we missing a lot? We shall pick this again later, with more details to it.
Types of Model Drift in Machine Learning
Data Drift & Concept Drift:
Now let’s talk about data drift and concept drift. Data drift is a very general terminology, which has a common interpretation across, whereas, concept drift is something which makes us think/re-think about the underlying domain know-how. Today, whoever thinks of starting their digitalization journey has a very fundamental question in their mind – whether or not the data is sufficient to build the machine learning model? The answer to this could be both yes and no, and it really depends on the methodology and the assumptions one had made while developing the model. Let us try to understand this with a simple example.
Data Drift:
Let’s assume you have used a standard scaler in one of your predictive maintenance or quality prediction or any other similar Machine learning/AI project. Which means that, for all the data points you’re transforming your sensor data/failure data/quality data based on the below equation:
Essentially we are transforming our dataset in such a way that for every process parameters in X has a mean of 0 and standard deviation of σ. Before we move ahead, one has to be conceptually clear about the difference between the sample and the population. Population is entire group of possibilities of scenarios, whereas the sample is the subset of the population. Generally, we assume that no two samples drawn at random are different from each other. Which means that we also assume that the mean and SD of the population is equal to that of any random sample which we draw from the entire dataset.
To understand it in much better way, let us take the example of the Heat exchanger predictive maintenance. The population dataset is the entire dataset inclusive of the process parameters, downtimes, maintenance records right from the day 0 of the process. The sample of the dataset could be the last 1 year data. One of the reasons why we are selecting only last 1 year data could be that – maybe the data is not available for the process since the beginning, as it was not stored. So, one is forced to assume that the mean and SD of the past 1 year data is representative of the entire span, which could be a wrong expectation.
Let’s say you have developed the machine learning model on top of this transformed dataset, with an acceptable level accuracy for training/validation/cross validation dataset, and deployed the model in real-time exposed to the live data. Here the model will transform the new data with the same mean and SD which was used at the stage of training period. And, there is a high chance that the behavior (mean and SD) of your new dataset is very different than what you had estimated using the training dataset. This scenario will ultimately cause the performance degradation in your deployed model. This is what data drift means in process industry. The reason for this could be insufficient data in the training set, or any other on similar lines. Same thing applies to multiple scenarios like – MinMax Scaler, or any other scaler. MinMax scaler is based on the minimum and maximum value observed from the dataset, which could be completely different among the training, validation and testing sample dataset.
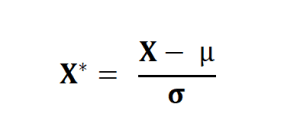
In the above example, we used the impact of scaling techniques to demonstrate the data drift, but like this, there could be multiple reasons for data drift, which brings in the requirement for not only looking into the model performance metrics but also into the data itself in a prudent way.
Concept Drift:
This happens when the concept, over the course of time changes. Which essentially means that the process data model (Machine learning) has yet not learnt the exact physics from the data? The reason for this could be multiple, such as insufficient volume of data considered for the training purpose. For Example, during the stage of step test in the APC implementation one may end up with an incomplete set of dataset, which could be misleading, as not all scenarios were considered for the learning purpose. Point to note here is that model is able to predict only those scenarios over which it was trained. So, if for some reason the training dataset doesn’t consist of certain specific scenarios, then model is susceptible to misinterpret and mislead the predictions. Let us continue with the example of heat exchanger, where the failure could be due to corrosion (A), mechanical issues (B), or improper maintenance (C). Now let’s assume that the training data consisted of the process parameters, failure logs and others contained only the information of the first 2 failure codes. So it still doesn’t know that there could be a possibility of failure due to improper maintenance (C). So, when deployed, model wouldn’t even predict C, even though there was an actual C. Also, we would have got a training, validation accuracy of more than 90/95%, but it was only considering the binary outcomes – A or B. By now, you must have had realized that even though the model performed so well while training, but during go-live it misinterpreted and misclassified the outcomes over which it was not trained upon. The essentially makes to rethink about the concept (scenarios) which we expected it to predict, but we didn’t feed it.
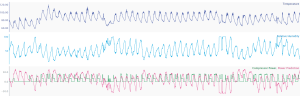
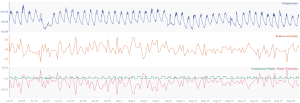
Fig-1. (a) Represents the good fit for training on dataset where relative humidity is centred around 50, (b) Represents the incorrect predictions due to drift in the values of relative humidity
Another classical example could be that of a process where we have temperature, pressure, flow, level, volume parameters, and we intend to predict the quality variable Y in real-time. Now, assume that in the training/validation dataset the variability of level and volume is not observed, which makes the machine learning model to assume that these parameters remain almost constant. (Assuming we are focusing on the production scale process, which is a set process, where the volume or the level doesn’t change appreciably during the operational period). So, by nature the model will set less weightage to these parameters, and will by default give them the least weightage. But from physics, we may know that there is a huge impact of level and volume on Y. But since the mathematical model doesn’t have this intellect, it will drop these parameters for prediction, and when we have a scenario of a volume or level change, this model will misinterpret the relationship and will predict the wrong outcomes. To counter such challenges, we have a variety of routes to bring this intelligence into the model, of which one can be as simple as gathering more and more data, until and unless all of the required scenarios are captured. Or, one can generate the synthetic data using steady-state, dynamic simulations which could one of the closest approximations to the real-life scenarios. Or, one may plan to set the first-principle constraint on the outcomes of the model, which can ensure that fundamentals of physics are not violated by any means.
We hope this article will help you to nurture and accelerate your process data model in a more refined way.
- Published in Blog

Steel Coil Processing: Scheduling and Performance

- Published in Metals and Mining


