
Machine learning by definition is a relationship which is established between a set of input variables and an output variable. Specifically, in process industry identification of this relationship becomes a difficult task, as it becomes highly non-linear at cases. The internal dynamics and behavior of the operator operating the process is something that comes under the interest of the ML/AI models. It tries to capture all of such instances which can be realized through the data it has been exposed to.
What’s Drifting in your Process – Data or Concept?
In this article, we are going to look into a very interesting and important concept of data-driven/Machine learning techniques. With the rapid development in technologies, industries have figured out multiple ways to estimate the performance of their deployed Machine learning/AI solution. One among them is drift – data drift and concept drift. Today, almost every industry is sitting on their-own data mine, longing enough to extract whatever information they could derive out of it. But, with such a surge in the industrial applications, it has also brought to our knowledge that there are lot many challenges involved at various levels of implementation. These challenges start right from the data itself – Integrity of the data, behavior and distribution of the data and so on. Sometimes, we end up spending most of our time in developing the process model (Machine learning model), which performs too well on the training dataset, but when tested on the live data- its performance drastically reduces. What do you think, what could have gone wrong here? Are we missing something or are we missing a lot? We shall pick this again later, with more details to it.
Types of Model Drift in Machine Learning
Data Drift & Concept Drift:
Now let’s talk about data drift and concept drift. Data drift is a very general terminology, which has a common interpretation across, whereas, concept drift is something which makes us think/re-think about the underlying domain know-how. Today, whoever thinks of starting their digitalization journey has a very fundamental question in their mind – whether or not the data is sufficient to build the machine learning model? The answer to this could be both yes and no, and it really depends on the methodology and the assumptions one had made while developing the model. Let us try to understand this with a simple example.
Data Drift:
Let’s assume you have used a standard scaler in one of your predictive maintenance or quality prediction or any other similar Machine learning/AI project. Which means that, for all the data points you’re transforming your sensor data/failure data/quality data based on the below equation:
Essentially we are transforming our dataset in such a way that for every process parameters in X has a mean of 0 and standard deviation of σ. Before we move ahead, one has to be conceptually clear about the difference between the sample and the population. Population is entire group of possibilities of scenarios, whereas the sample is the subset of the population. Generally, we assume that no two samples drawn at random are different from each other. Which means that we also assume that the mean and SD of the population is equal to that of any random sample which we draw from the entire dataset.
To understand it in much better way, let us take the example of the Heat exchanger predictive maintenance. The population dataset is the entire dataset inclusive of the process parameters, downtimes, maintenance records right from the day 0 of the process. The sample of the dataset could be the last 1 year data. One of the reasons why we are selecting only last 1 year data could be that – maybe the data is not available for the process since the beginning, as it was not stored. So, one is forced to assume that the mean and SD of the past 1 year data is representative of the entire span, which could be a wrong expectation.
Let’s say you have developed the machine learning model on top of this transformed dataset, with an acceptable level accuracy for training/validation/cross validation dataset, and deployed the model in real-time exposed to the live data. Here the model will transform the new data with the same mean and SD which was used at the stage of training period. And, there is a high chance that the behavior (mean and SD) of your new dataset is very different than what you had estimated using the training dataset. This scenario will ultimately cause the performance degradation in your deployed model. This is what data drift means in process industry. The reason for this could be insufficient data in the training set, or any other on similar lines. Same thing applies to multiple scenarios like – MinMax Scaler, or any other scaler. MinMax scaler is based on the minimum and maximum value observed from the dataset, which could be completely different among the training, validation and testing sample dataset.
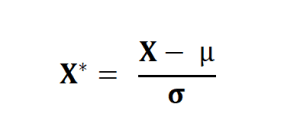
In the above example, we used the impact of scaling techniques to demonstrate the data drift, but like this, there could be multiple reasons for data drift, which brings in the requirement for not only looking into the model performance metrics but also into the data itself in a prudent way.
Concept Drift:
This happens when the concept, over the course of time changes. Which essentially means that the process data model (Machine learning) has yet not learnt the exact physics from the data? The reason for this could be multiple, such as insufficient volume of data considered for the training purpose. For Example, during the stage of step test in the APC implementation one may end up with an incomplete set of dataset, which could be misleading, as not all scenarios were considered for the learning purpose. Point to note here is that model is able to predict only those scenarios over which it was trained. So, if for some reason the training dataset doesn’t consist of certain specific scenarios, then model is susceptible to misinterpret and mislead the predictions. Let us continue with the example of heat exchanger, where the failure could be due to corrosion (A), mechanical issues (B), or improper maintenance (C). Now let’s assume that the training data consisted of the process parameters, failure logs and others contained only the information of the first 2 failure codes. So it still doesn’t know that there could be a possibility of failure due to improper maintenance (C). So, when deployed, model wouldn’t even predict C, even though there was an actual C. Also, we would have got a training, validation accuracy of more than 90/95%, but it was only considering the binary outcomes – A or B. By now, you must have had realized that even though the model performed so well while training, but during go-live it misinterpreted and misclassified the outcomes over which it was not trained upon. The essentially makes to rethink about the concept (scenarios) which we expected it to predict, but we didn’t feed it.
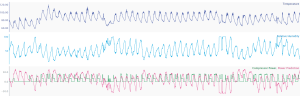
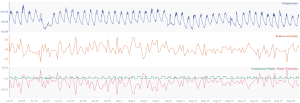
Fig-1. (a) Represents the good fit for training on dataset where relative humidity is centred around 50, (b) Represents the incorrect predictions due to drift in the values of relative humidity
Another classical example could be that of a process where we have temperature, pressure, flow, level, volume parameters, and we intend to predict the quality variable Y in real-time. Now, assume that in the training/validation dataset the variability of level and volume is not observed, which makes the machine learning model to assume that these parameters remain almost constant. (Assuming we are focusing on the production scale process, which is a set process, where the volume or the level doesn’t change appreciably during the operational period). So, by nature the model will set less weightage to these parameters, and will by default give them the least weightage. But from physics, we may know that there is a huge impact of level and volume on Y. But since the mathematical model doesn’t have this intellect, it will drop these parameters for prediction, and when we have a scenario of a volume or level change, this model will misinterpret the relationship and will predict the wrong outcomes. To counter such challenges, we have a variety of routes to bring this intelligence into the model, of which one can be as simple as gathering more and more data, until and unless all of the required scenarios are captured. Or, one can generate the synthetic data using steady-state, dynamic simulations which could one of the closest approximations to the real-life scenarios. Or, one may plan to set the first-principle constraint on the outcomes of the model, which can ensure that fundamentals of physics are not violated by any means.
We hope this article will help you to nurture and accelerate your process data model in a more refined way.


