This article should help you to set a benchmark for how to decisively deploy ML/AI models considering your investments to be in the right software infrastructure/architecture/platform, guiding all through your journey of manufacturing analytics. Deployment of any model is a strong function of the data stream including its quality – Accuracy, completeness & consistency (Covered in earlier article) and volume, sampling rate and its ultimate end-objective that will decide on how the end user is going to consume the analytics output.
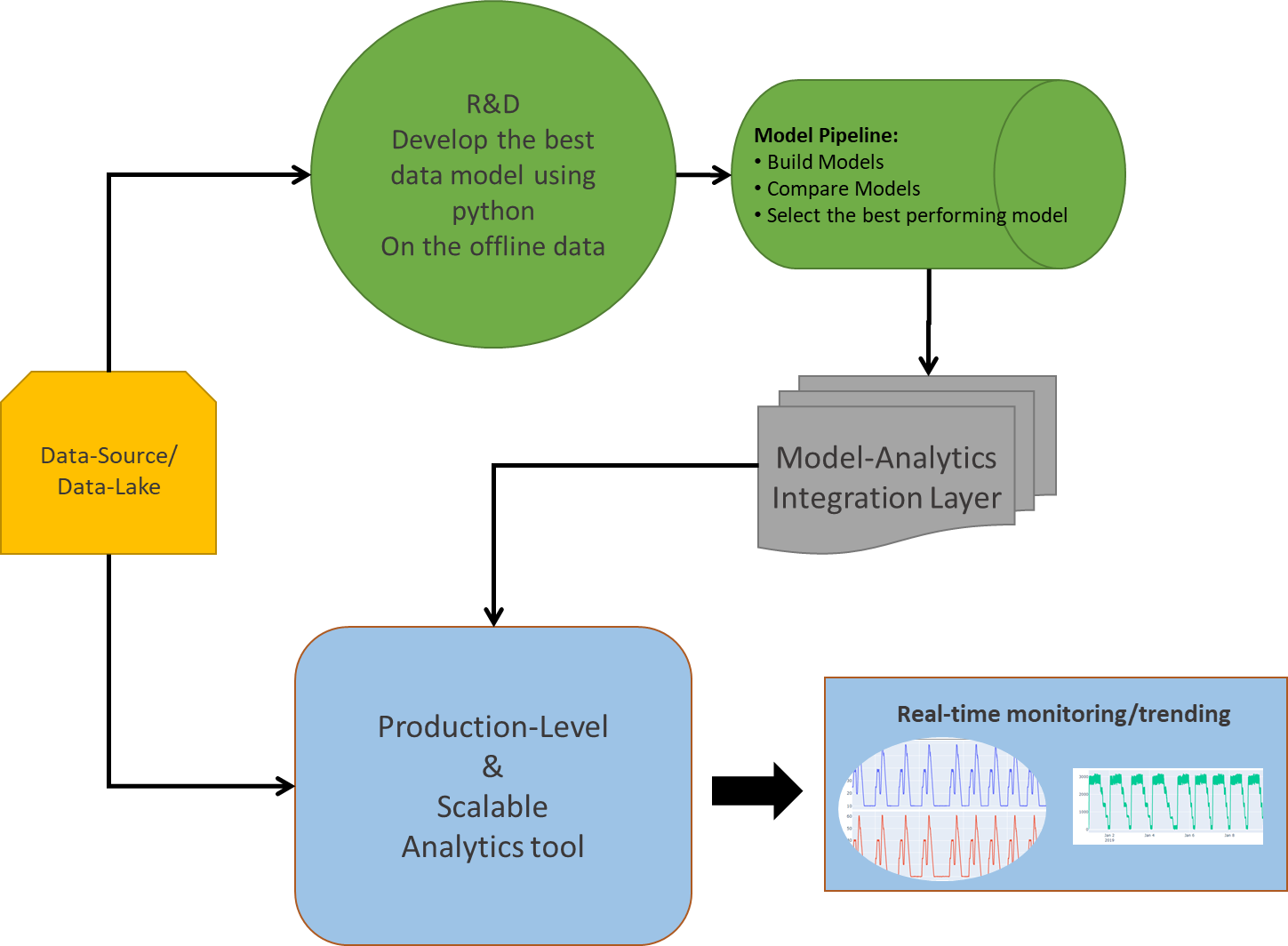
Fig: Deployment of ML/AI solution-Architecture
A major challenge for any deployment solution lies in its CAPEX and OPEX that goes behind developing the environment/infrastructure ready for analytics at site. This concludes not only with a huge investment in building data infrastructure (Eg-process historians/data-lake for big data storage, processing and analytics), but also keeping the one updated (Integrated) with the newest possible technology around the world for better performance.
Let’s get into a detailed understanding about various options and a few challenges in deploying the right analytics solution.
Deployment Options:
When it comes to the deployment of any analytics solution, we need to be selective about “how the end-user is going to consume its output?” or in simple sense harvesting your Analytics.
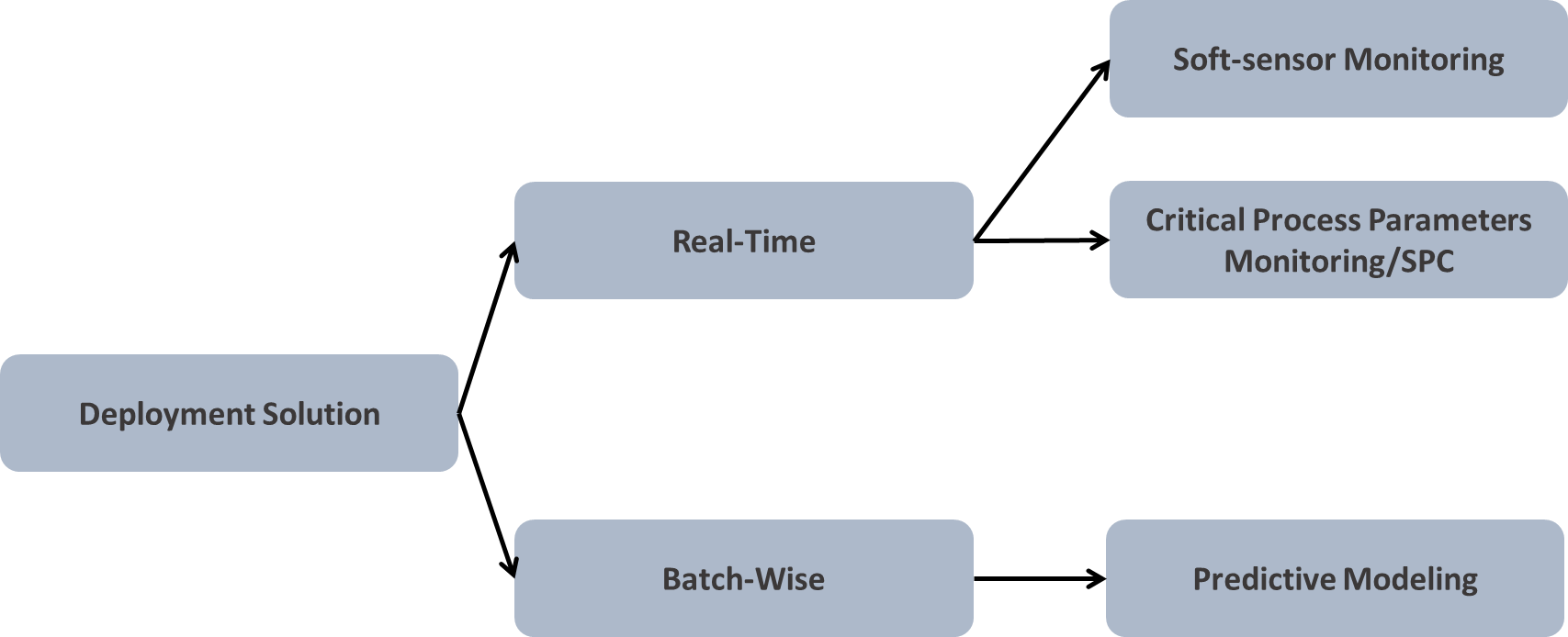
Fig: Kind of deployment (1)Real-Time, (2)Batch Data-wise
The answer to the above could be either visual analytics or predictive analytics using soft-sensor modelling, if feasible or by predicting on the batch of the dataset. Visual analytics can sometimes speak more about the uncertainties/abnormalities if the underlying dataset is a good representation of your operational strategy.
Real-time model deployment is not always feasible due to many of its limitations. Training-cross validating-testing the model is a time intensive and expensive task. At this point you may have a question in mind, “What if soft-sensors signal is created”? This is a pretty intuitive question (Assuming that most of the manufacturing analytics will involve regression model over classification tasks). So, in-order to set a context here, I will say, yes you are absolutely right!! One can create a soft-sensor signal to monitor the real operations, but only with a few limited models out there. Not all models will give you a regression line equation for building a soft-signal. For Eg: Random forest will enable you will the prediction, but being a tree predictor in its core, it won’t give you the regression coefficients for the parameters. And similar kind of behaviour is expected from many other ML/AI models. On the other hand, if you’re building a linear regression or polynomial model, it will give you the predictor’s parameters, which you can copy and build a corresponding soft-sensor for real-time calculations.
Many a times, it’s being observed that identifying the Critical Process Parameters and creating a statistical limit around it will give us a better outcome. For Eg: After applying a regression model you should be able to estimate the important parameters for prediction, upon which you can create a statistical limit of let’s say, ±1 or 2 σ for controlled operations (Assuming that the defined statistical limits are validated and tested on the real dataset).
One platform-scalable solution:
Selection of the right platform, which is scalable across all of the assets and processes, is required for efficient analytics in the production environment. To retain maximum fraction of the investments and benefits from your analytics a single solution/platform should be identified that provides you all the capabilities without much limitation. There are a few key capabilities that you should be looking for before selecting a platform,
- Easy and intuitive solution
- Should be able to handle most of the analytics requirements
- Should easily connect with multiple data-sources/data-lake at a single place
- Data connectivity to the real-time should be quick, without much delay
- Should be capable of performing data cleaning functionalities
- Capable of creating the soft-sensors/advanced mathematical operations
- Advanced visualizations
- Functionalities such as SPC/hidden pattern search/deviations should be packaged
- Should come with modelling capabilities, by enabling easy integration with python/R/Matlab programming languages.
- Provide a dashboard view (dynamic/static) for higher management, to enable them with easy decision making power.
- Above all, the analytics performed on one asset should be easily scalable across all the other assets.
R&D V/S Production Scale:
When it comes to the Production scale, the deployment of the analytics is limited by various elements such as, the databases, whether time-series or SQL, modelling capabilities, whether Python or R, the platform architecture, whether light environment or not. All of these functionalities should be considered in mind before deploying any architecture.
One key thing that we might miss out easily is that the platform should have the capability to provide the output in various formats, considering the end-user. It could be for operators, or for the engineers, M&ST team, operational intelligence team, or the higher management.
On the other hand, python being a fantastic modeling environment requires a lot of coding and modeling experience, which is not feasible for all the users. Although it’s pretty good choice for R&D level of analytics, where the user himself is expected to code-compute-create-model and consume the output of the offline data analytics. Also, modeling in python requires many other dependencies/packages which aids in fast coding, but at the expense of the processing power and speed. Its most suitable for the user who wants to try and check many new models out there in the market to compare its performance with the existing models.
Assuming a modeling project, to streamline the idea of scalability, one must starts with modeling in the python environment and then somehow transforming its outcome into the analytics platform by either creating the soft-sensors or estimating the important process parameters and layering the limits over it. One other approach could be to train and validate the model on the sufficient offline dataset, and then from time to time test the model on the newly generated dataset to check its predictive power and estimate the outcomes, and if required go back and tune the model parameters until you get a satisfactory result with maximum accuracy.
To conclude, python should be selected, only for the research oriented modeling projects and not for the production level (deployment) analytics. Moreover, many new and existing technologies are available that provides to us with an easy python/R/Matlab integration capabilities within themselves, such as Seeq-To which you can write down your python scripts in Seeq Datalabs (Similar to jupyter Notebook) and model on the choice of data that you are connected with.


